
Selamat datang di tutorial pertama Natural Language Processing (NLP) dengan menggunakan deep learning. Tujuan dari tutorial ini adalah untuk memberikan bahan pembelajaran yang mudah dipahami agar siapa saja dapat mengaplikasikan deep learning dalam kasus NLP. Tutorial ini dapat diikuti siapa saja yang sudah memiliki pengetahuan terkait bahasa pemrograman Python. Disini kita akan mempelajari NLP dengan menggunakan contoh data riil yang mudah diikuti. Hal-hal yang akan kita bahas di dalam tutorial ini adalah sebagai berikut:
Outline
Pertama-tama mari mulai dengan contoh sederhana dalam pendeteksian emosi. Mari lihat dua contoh dibawah ini:

Manakah dari kedua contoh tersebut yang lebih mengutarakan kekecewaan? Ya, tentu kalimat yang kedua. Contoh ini nampak mudah bagi kita sebagai manusia, namun bagaimanakah kita dapat mengajarkan cara berpikir seperti ini pada komputer?
Deep Learning di NLP
Transisi dari sistem berbasis aturan ke deep learning
Selama beberapa dekade ke belakang, praktisi di bidang NLP fokus membangun aturan-aturan untuk menangkap gramatika dari setiap bahasa. Langkah ini sangatlah sulit dan memakan banyak waktu sampai suatu momen dimana model-model statistik mulai digunakan di bidang NLP. Model-model tersebut dibangun untuk mempelajari suatu fungsi yang memetakan suatu masukan ke suatu nilai keluaran. Dalam beberapa tahun terakhir, model-model deep learning menunjukan progres yang signifikan di bidang NLP, terutama sejak keberadaan framework-framework deep learning yang open source seperti PyTorch.
Solusi sederhana untuk aplikasi NLP adalah dengan aturan keyword matching. Dalam contoh kasus pendeteksian emosi, kita dapat mengumpulkan kata-kata yang merepresentasikan senang, sedih, dan lainnya. Untuk setiap kalimat yang memiliki kata-kata paling banyak terkait suatu emosi, kita dapat mengklasifikasikannya ke dalam kategori emosi tersebut. Apakah itu cara yang terbaik yang dapat kita lakukan? Dibandingkan melakukan pengecekan kemunculan kata, dengan menggunakan deep learning kita dapat melatih model yang dapat menerima masukan kalimat dan memprediksi emosi bergantung arti semantik dari kalimat tersebut.
Untuk memperlihatkan perbedaan kedua metode tersebut, mari lihat kembali contoh sebelumnya!
Dengan melakukan pengecekan kata, kita dapat dengan mudah mengelabui model untuk mengklasifikasi emosi pada kalimat kedua sebagai senang karena terdapat frasa memenangkan undian. Jika model tersebut dapat memahami arti dari kalimat kedua, maka model dapat dengan mudah mengetahui perubahan makna setelah klausa pertama dimana orang yang mengatakan kalimat tersebut sedih karena ia tidak memenangkan undian.
Sebelum masuk ke pemodelan deep learning model dengan PyTorch, kita akan membahas sedikit lebih jauh mengenai jenis-jenis task di NLP.
Kategori task dibidang NLP
Dibidang NLP, terdapat banyak task yang dapat dicapai. Kita dapat membagi task-task tersebut kedalam beberapa kategori sebagai berikut
- Text Classification
Klasifikasi dokumen dengan sebuah label. Contoh pendeteksian emosi sebelumnya adalah salah satu contoh dari kategori ini. Kita memprediksi label emosi bergantung dari kalimat yang diberikan. - Sequence Labeling
Kategori task ini melakukan prediksi label untuk setiap token dalam teks masukan. Task yang paling umum dalam kategori ini adalah Named Entity Recognition yang bertujuan untuk mendeteksi token pada kalimat masukan mana yang merupakan nama dari suatu entitas named entities. - Language Generation
Dalam kategori task ini, model akan menghasilkan serangkaian kalimat baru berdasarkan kalimat masukan yang diberikan. Salah satu contoh dari kategori ini adalah mesin penjawab pertanyaan, dimana model menerima pertanyaan masukan dan konteks pertanyaan sebagai masukan dan menghasilkan kalimat jawaban dari pertanyaan tersebut.
Dalam tutorial ini, kita akan melihat contoh aplikasi deep learning pada kategori text classification. Jika kamu baru pertama kali belajar deep learning, ini akan menjadi jalan pintas untuk mempelajari model deep learning pada kasus NLP dengan menggunakan PyTorch.
Membangun model NLP dengan PyTorch
Kita akan mulai dari contoh sederhana. Disini kita akan menggunakan model yang telah dilatih sebelumnya (pre-trained model), dan kemudian melakukan penyesuaian (fine-tuning) pada pre-trained model tersebut. Pada contoh ini kita akan menggunakan contoh langsung berbahasa Indonesia dengan menggunakan micro-framework IndoNLU yang dibangun diatas framework deep learning, PyTorch.
Apa itu Pytorch?
PyTorch adalah salah satu open-source framework deep learning terbaik yang dibangun diatas Python dan CUDA berdasarkan pada library Torch. PyTorch umum digunakan untuk riset dan juga aplikasi-aplikasi di bidang NLP, computer-vision, pemrosesan audio, dan lain-lain. PyTorch adalah salah satu framework deep learning yang paling sering digunakan oleh di riset-riset akademik dan juga di industri. PyTorch akan sangat mudah dipelajari bagi para pengguna Numpy dikarenakan struktur data dasar dari PyTorch, torch.Tensor, sangat mirip dengan numpy array pada library Numpy. Hal utama yang membedakan torch.Tensor dengan numpy array adalah kemampuan dari torch.Tensor untuk melakukan operasi pada CPU dan CUDA. Hal ini membuat PyTorch menjadi sebuah framework yang jauh lebih baik untuk deep learning dibandingkan dengan Numpy. Selain itu, PyTorch juga memiliki kapabilitas untuk membangun graf komputasi yang dinamis sehingga kita dapat melakukan debugging model yang dibangun dengan mudah dan struktur model dapat diubah kapan saja. Hal ini menjadi kelebihan besar dari PyTorch dibandingkan dengan framework deep learning seperti TensorFlow yang memiliki graf komputasi yang statis.
PyTorch dapat diinstall dan digunakan hampir diseluruh sistem operasi dengan menggunakan Anaconda atau pip.
Bila menggunakan Anaconda, PyTorch dapat diinstall dengan cara mengeksekusi perintah berikut
conda install pytorch torchvision -c pytorch
Bila menggunakan pip, PyTorch dapat diinstall dengan cara mengeksekusi perintah berikut
pip install torch torchvision
Untuk menggunakan PyTorch pada kode Python kita dapat lakukan dengan melakukan import modul PyTorch
import torch
Dataset Sentiment Analysis
Sebagai contoh kasus, dalam tutorial ini kita akan menggunakan dataset sentiment analysis. Sentiment analysis merupakan salah satu task yang paling populer di NLP. Dalam sentiment analysis kita akan membangun model yang dapat mendeteksi sentimen dalam sebuah kalimat. Umumnya, sentimen memiliki tiga nilai polaritas yaitu positif, negatif, dan netral. Di berbagai industri, sangatlah menguntungkan jika dapat menganalisa review dari pelanggan secara otomatis. Review-review tersebut dapat berasal dari berbagai macam platform sosial seperti Twitter, Zomato, TripAdvisor, Facebook, Instagram, dan lain-lain. Dataset sentiment analysis yang akan kita gunakan berasal dari salah satu task di IndoNLU yang bernama SmSA. Mari kita mulai proyek sentiment analysis ini.
Data Preparation
Kita mulai proyek ini dengan persiapan data di PyTorch. Persiapan data adalah salah satu tahap yang paling penting dalam pemodelan. Secara umum, persiapan data memakan kurang lebih 60% dari total waktu untuk persiapan pemodelan. Untungnya, berbagai fungsi untuk melakukan data preprocessing, telah disediakan oleh PyTorch dan IndoNLU.
PyTorch menyediakan cara terstandarisasi untuk menyiapkan data untuk melakukan pemodelan. PyTorch menyediakan fitur-fitur canggih untuk memproses data dan untuk dapat menggunakan fitur-fitur tersebut, kita perlu menggunakan 2 kelas yang disediakan di PyTorch dalam modul torch.utils.data yaitu Dataset dan DataLoader. Dataset is sebuah abstract class yang perlu kita extend di PyTorch, kita akan mengoper objek dari kelas Dataset ke dalam objek dari kelas DataLoader. DataLoader adalah inti dari perangkat pemrosesan data di PyTorch. DataLoader menyediakan banyak fungsionalitas untuk mempersiapkan data termasuk berbagai metode sampling, komputasi paralel, dan pemrosesan terdistribusi. Untuk menunjukan bagaimana cara mengimplementasi Dataset dan DataLoader di PyTorch, kita akan melihat lebih dalam pada kelas DocumentSentimentDataset and DocumentSentimentDataLoader yang disediakan oleh IndoNLU dan dapat diakses di link berikut.
Sebelum masuk ke implementasi, kita perlu mengetahui format dari dataset sentiment analysis yang kita gunakan. Dataset SmSA yang akan kita gunakan tersimpan dalam format tsv dan terdiri dari 2 kolom, yaitu: text dan sentiment. Berikut adalah contoh dari data pada dataset SmSA

Mari kita mulai mempersiapkan pipeline pemrosesan data. Pertama-tama, mari kita import modul-modul yang diperlukan
from torch.utils.data import Dataset, DataLoader
Berikutnya, kita akan mengimplementasi kelas DocumentSentimentDataset untuk data loading. Untuk membuat kelas DocumentSentimentDataset yang fungsional, kita perlu mengimplementasikan 3 fungsi, yaitu __init__(self, ...), __getitem__(self, index), dan __len__(self).
Pertama-tama, mari kita implementasikan fungsi ` init(self, …)`
class DocumentSentimentDataset(Dataset):
# Static constant variable
LABEL2INDEX = {'positive': 0, 'neutral': 1, 'negative': 2} # Map dari label string ke index
INDEX2LABEL = {0: 'positive', 1: 'neutral', 2: 'negative'} # Map dari Index ke label string
NUM_LABELS = 3 # Jumlah label
def load_dataset(self, path):
df = pd.read_csv(path, sep=’\t’, header=None) # Baca tsv file dengan pandas
df.columns = ['text','sentiment'] # Berikan nama pada kolom tabel
df['sentiment'] = df['sentiment'].apply(lambda lab: self.LABEL2INDEX[lab]) # Konversi string label ke index
return df
def __init__(self, dataset_path, tokenizer, *args, **kwargs):
self.data = self.load_dataset(dataset_path) # Load tsv file
# Assign tokenizer, disini kita menggunakan tokenizer subword dari HuggingFace
self.tokenizer = tokenizer
Sekarang kita sudah memiliki data dan tokenizer yang didefinisikan difungsi __init__(self, ...). Selanjutnya kita akan mengimplementasikan fungsi __getitem__(self, index) dan __len__(self).
def __getitem__(self, index):
data = self.data.loc[index,:] # Ambil data pada baris tertentu dari tabel
text, sentiment = data['text'], data['sentiment'] # Ambil nilai text dan sentiment
subwords = self.tokenizer.encode(text) # Tokenisasi text menjadi subword
# Return numpy array dari subwords dan label
return np.array(subwords), np.array(sentiment), data['text']
def __len__(self):
return len(self.data) # Return panjang dari dataset
Ya, kita sudah mengimplementasikan seluruh fungsi pada DocumentSentimentDataset. Definisi lengkap dari DocumentSentimentDataset adalah seperti berikut:
class DocumentSentimentDataset(Dataset):
# Static constant variable
LABEL2INDEX = {'positive': 0, 'neutral': 1, 'negative': 2} # Map dari label string ke index
INDEX2LABEL = {0: 'positive', 1: 'neutral', 2: 'negative'} # Map dari Index ke label string
NUM_LABELS = 3 # Jumlah label
def load_dataset(self, path):
df = pd.read_csv(path, sep=’\t’, header=None) # Baca tsv file dengan pandas
df.columns = ['text','sentiment'] # Berikan nama pada kolom tabel
df['sentiment'] = df['sentiment'].apply(lambda lab: self.LABEL2INDEX[lab]) # Konversi string label ke index
return df
def __init__(self, dataset_path, tokenizer, *args, **kwargs):
self.data = self.load_dataset(dataset_path) # Load tsv file
# Assign tokenizer, disini kita menggunakan tokenizer subword dari HuggingFace
self.tokenizer = tokenizer
def __getitem__(self, index):
data = self.data.loc[index,:] # Ambil data pada baris tertentu dari tabel
text, sentiment = data['text'], data['sentiment'] # Ambil nilai text dan sentiment
subwords = self.tokenizer.encode(text) # Tokenisasi text menjadi subword
# Return numpy array dari subwords dan label
return np.array(subwords), np.array(sentiment), data['text']
def __len__(self):
return len(self.data) # Return panjang dari dataset
Perhatikan bahwa subwords yang dikembalikan oleh dataset dapat memiliki panjang yang berbeda-beda untuk setiap index. Untuk dapat diproses secara paralel oleh model, kita perlu menstandarisasi panjang dari subwords dengan memotong beberapa subwords atau menambahkan padding token. Untuk itu kita perlu mengimplementasikan DocumentSentimentDataLoader.
Untuk mendapatkan fungsi yang sesuai dengan apa yang kita butuhkan, kita dapat meng-override fungsi collate_fn(self, batch) dari kelas DataLoader. collate_fn() adalah fungsi yang akan dipanggil setelah dataloader mengumpulkan satu batch data dari dataset. Argumen batch pada fungsi collate_fn berisi list data yang dikembalikan dari Dataset.__getitem__(). Fungsi collate_fn(self, batch) kita memproses list subword dan sentiment dan mengeluarkan padded_subword, mask, dan sentiment. mask adalah suatu variabel yang digunakan untuk mencegah model memproses padding token sebagai bagian dari masukan. Untuk memudahkan, visualisasi berikut menunjukan proses transformasi subword masukan menjadi subword yang telah di padding beserta masknya.

Dari gambar diatas, angka 0 pada subword keluaran menandakan padding token, sedangkan nilai lainnya adalah nilai dari subword masukan. Variable mask terdiri dari dua buah nilai, 0 and 1, dimana 0 berarti token tidak perlu masuk dalah perhitungan model dan 1 berarti token yang perlu diperhitungkan. OK, sekarang mari kita implementasikan kelas DocumentSentimentDataLoader.
class DocumentSentimentDataLoader(DataLoader):
def __init__(self, max_seq_len=512, *args, **kwargs):
super(DocumentSentimentDataLoader, self).__init__(*args, **kwargs)
self.max_seq_len = max_seq_len # Assign batas maksimum subword
self.collate_fn = self._collate_fn # Assign fungsi collate_fn dengan fungsi yang kita definisikan
def _collate_fn(self, batch):
batch_size = len(batch) # Ambil batch size
max_seq_len = max(map(lambda x: len(x[0]), batch)) # Cari panjang subword maksimal dari batch
max_seq_len = min(self.max_seq_len, max_seq_len) # Bandingkan dengan batas yang kita tentukan sebelumnya
# Buat buffer untuk subword, mask, dan sentiment labels, inisialisasikan semuanya dengan 0
subword_batch = np.zeros((batch_size, max_seq_len), dtype=np.int64)
mask_batch = np.zeros((batch_size, max_seq_len), dtype=np.float32)
sentiment_batch = np.zeros((batch_size, 1), dtype=np.int64)
# Isi semua buffer
for i, (subwords, sentiment, raw_seq) in enumerate(batch):
subwords = subwords[:max_seq_len]
subword_batch[i,:len(subwords)] = subwords
mask_batch[i,:len(subwords)] = 1
sentiment_batch[i,0] = sentiment
# Return subword, mask, dan sentiment data
return subword_batch, mask_batch, sentiment_batch
Horeee!! Kita sudah berhasil mengimplementasikan kelas DocumentSentimentDataLoader. Sekarang mari kita coba integrasikan kelas DocumentSentimentDataset and DocumentSentimentDataLoader. Kita dapat menginisialisasi kelas DocumentSentimentDataset and DocumentSentimentDataLoader dengan cara berikut ini:
dataset = DocumentSentimentDataset(‘./sentiment_analysis.csv’, tokenizer)
data_loader = DocumentSentimentDataLoader(dataset=dataset, max_seq_len=512, batch_size=32 num_workers=16, shuffle=True)
Kemudian kita bisa mengambil data dari dataloader dengan cara berikut:
for (subword, mask, label) in data_loader:
…
Sangat mudah bukan? Seperti yang kita lihat, pada parameter instansiasi kelas DocumentSentimentDataLoader, ada beberapa parameter lain selain max_seq_len. Parameter dataset adalah parameter wajib untuk kelas DataLoader dan akan digunakan sebagai sumber data. batch_size menandakan jumlah data yang akan diambil pada setiap batch, num_workers menandakan jumlah proses yang akan kita gunakan untuk mengambil data secara paralel, and shuffle menandakan jika kita ingin mengambil data secara terurut atau acak.
Pada sesi selanjutnya, kita akan menggunakan DocumentSentimentDataset dan DocumentSentimentDataLoader dalam proses pemodelan
Model
Untuk kebutuhan pemodelan, kita akan menggunakan salah satu model yang paling terkenal saat ini di bidang NLP yang bernama BERT (Bidirectional Encoder Representations from Transformers). Sesuai dengan namanya, BERT merupakan model berbasis transformer, mekanisme attention yang memperhitungan relasi kontekstual antar kata dari sebuah kalimat. Sebelum BERT, model-model yang populer adalah model berbasis RNN (recurrent neural network), yang memproses input text secara sekuensial. Hal yang membuat BERT lebih baik dari model berbasis RNN adalah BERT model tidak berdasarkan pada markov assumption dan menggunakan mekanisme self-attention.
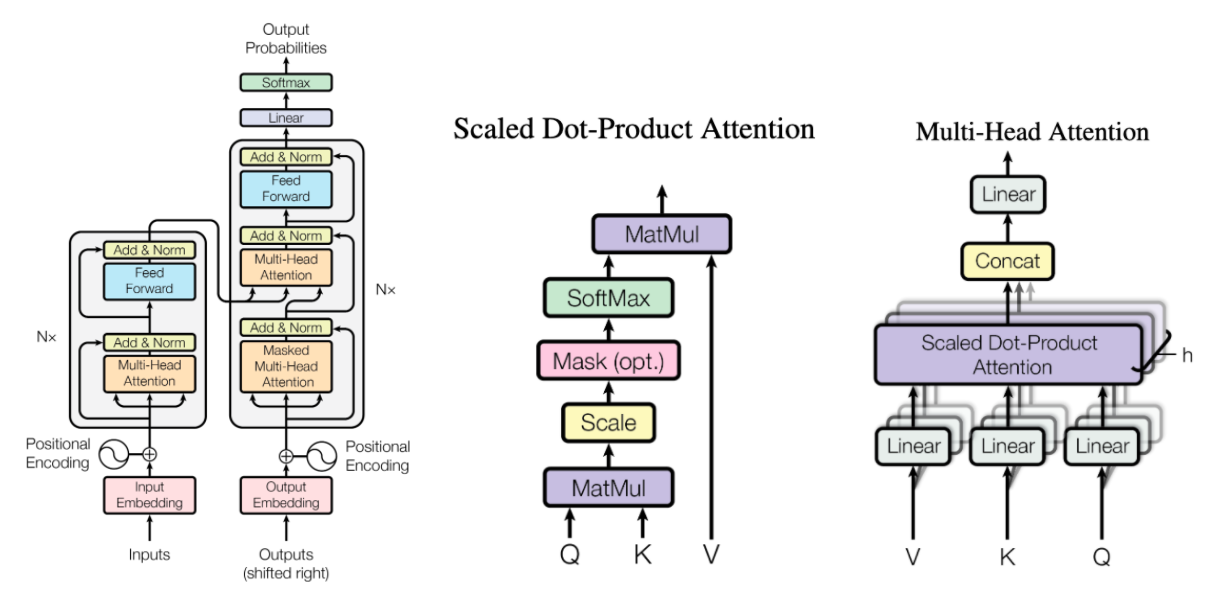
Untuk melatih model, kita dapat melakukan training tidak dari awal, yaitu dengan menggunakan model yang telah dilatih sebelumnya dan hanya belajar sedikit lagi untuk mencapai titik optimal pada task yang baru. Teknik training ini disebut sebagai fine-tuning. Dengan cara ini, kita tidak perlu melakukan training dari awal, tetapi kita dapat mendownload model yang telah dilatih sebelumnya (pre-trained model) dari IndoNLU, pada tutorial ini kita akan menggunakan pre-trained model indobenchmark/indobert-base-p1.
Sekarang, kita akan mengambil pre-trained model dari IndoNLU yang dapat diakses melalui platform Hugging-Face. Terima kasih IndoNLU dan Hugging-Face! Untuk tutorial analisa sentimen ini, kita akan melakukan fine-tuning dengan menggunakan kelas model BertForSequenceClassification dari library transformers milik HuggingFace.
from transformers import BertConfig, BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained("indobenchmark/indobert-base-p1")
config = BertConfig.from_pretrained("indobenchmark/indobert-base-p1")
Model = BertForSequenceClassification.from_pretrained("indobenchmark/indobert-base-p1", config=config)
Selesai! Sekarang kita sudah memiliki indobert-base-p1 tokenizer dan model yang sudah siap untuk di fine-tune.
Fase Training
Di sini, kita akan melakukan fine-tune pre-trained model indobert-base-p1 dengan data analisis sentimen.
Salah satu fitur esensial dari PyTorch adalah autograd. Sebelum, kita masuk ke dalam penjelasan mengenai training, kita perlu mengerti tugas dari autograd. Autograd adalah sebuah package yang menyediakan operasi diferensial otomatis pada Tensors. Framework ini secara otomatis digunakan untuk membangun graf komputasional yang diperlukan saat backpropagation.
Proses fine-tuning dilakukan dalam beberapa tahap:
Definisikan optimizer Adam dengan learning rate yang kecil, biasanya dibawah 1e-3
Panggil model.train() untuk mengaktifkan layer regularisasi dropout pada model
Panggil torch.set_grad_enabled(True) untuk mengaktifkan komputasi dengan autograd
Iterasi objek data loader train_loader untuk mengambil batch_data dan operkan pada fungsi forward forward_sequence_classification in the model.
Hitung gradien secara otomatis dengan memanggil fungsi loss.backward(). Fungsi ini adalah fungsi turunan dari autograd package.
Melakukan perhitungan gradien dengan memanggil optimizer.step()`
Kita dapat melihat bahwa poin-poin diatas dituliskan dalam skrip latihan di bawah ini yang nantinya akan kita gunakan untuk melakukan fine-tuning model.
optimizer = optim.Adam(model.parameters(), lr=3e-6)
model = model.cuda()
n_epochs = 5
for epoch in range(n_epochs):
model.train()
torch.set_grad_enabled(True)
total_train_loss = 0
list_hyp, list_label = [], []
train_pbar = tqdm(train_loader, leave=True, total=len(train_loader))
for i, batch_data in enumerate(train_pbar):
# Forward model
loss, batch_hyp, batch_label = forward_sequence_classification(model, batch_data[:-1], i2w=i2w, device='cuda')
# Update model
optimizer.zero_grad()
loss.backward()
optimizer.step()
tr_loss = loss.item()
total_train_loss = total_train_loss + tr_loss
# Calculate metrics
list_hyp += batch_hyp
list_label += batch_label
train_pbar.set_description("(Epoch {}) TRAIN LOSS:{:.4f} LR:{:.8f}".format((epoch+1),
total_train_loss/(i+1), get_lr(optimizer)))
# Calculate train metric
metrics = document_sentiment_metrics_fn(list_hyp, list_label)
print("(Epoch {}) TRAIN LOSS:{:.4f} {} LR:{:.8f}".format((epoch+1),
total_train_loss/(i+1), metrics_to_string(metrics), get_lr(optimizer)))
Skrip latihan di atas menggunakan fungsi forward_sequence_classification sebagai fungsi forward model. Berikut ini adalah potongan kode berisi bagian-bagian penting dari fungsi forward_sequence_classification.
def forward_sequence_classification(model, batch_data, i2w, is_test=False, device='cpu', **kwargs):
…
if device == "cuda":
subword_batch = subword_batch.cuda()
mask_batch = mask_batch.cuda()
token_type_batch = token_type_batch.cuda() if token_type_batch is not None else None
label_batch = label_batch.cuda()
# Forward model
outputs = model(subword_batch, attention_mask=mask_batch, token_type_ids = token_type_batch, labels=label_batch)
loss, logits = outputs[:2]
…
return loss, list_hyp, list_label
Pada skrip latihan dan fungsi forward diatas, kita menggunakan berbagai fitur PyTorch, seperti kemudahan untuk memindahkan tensor dari CPU ke GPU, fleksibilitas untuk mendefinisikan fungsi loss beserta perhitungan loss, dan juga kemudahan perhitungan gradien dan optimisasi model dengan menggunakan modul autograd dan optimizer. Ayo kita lihat beberapa informasi detail terkait kapabilitas yang telah kita gunakan.
CPU vs CUDA
model = model.cuda()
Melatih sebuah model yang memiliki lebih dari satu juta parameter seperti BERT memerlukan waktu berbulan-bulan. Operasi training ini dapat dijalankan secara paralel pada GPU hingga 100x lebih cepat. Untuk memenuhi kebutuhan ini, PyTorch telah menyiapkan cara mudah untuk kita memindahkan variabel tipe data tensor kami untuk dihitung (dan diakses) baik di CPU atau GPU. Ini dilakukan dengan memanggil metode .cuda () atau .cpu () di setiap object dari kelas tensor dan juga pada model, untuk memindahkan objek tersebut ke memori GPU dari memori CPU, atau sebaliknya.
Fungsi Loss
loss_fct = CrossEntropyLoss()
total_loss = 0
for i, (logit, num_label) in enumerate(zip(logits, self.num_labels)):
label = labels[:,i]
loss = loss_fct(logit.view(-1, num_label), label.view(-1))
total_loss += loss
Dengan framework PyTorch, kita dapat menggunakan fungsi loss buatan sendiri atau menggunakan fungsi loss yang disediakan didalam framework PyTorch. Membangun fungsi loss buatan sendiri di Pytorch tidaklah sulit, kita hanya perlu mendefinisikan fungsi yang membandingkan tensor logits keluaran dari model with tensor label dan dengan itu fungsi loss yang telah dibangun langsung memiliki kapabilitas yang sama seperti fungsi loss bawaan PyTorch (komputasi gradien otomatis, dll.). Dalam contoh di tutorial ini, kita menggunakan fungsi loss bawaan PyTorch yaitu CrossEntropyLoss(). Cross entropy loss dihitung dengan membandingkan seberapa sesuai distribusi probabilitas keluaran dari fungsi softmax dengan pengkodean one-hot dari label data yang seharusnya. Penggunaan fungsi loss ini sangatlah tepat dalam kasus sentiment analisis kita, karena fungsi loss ini mengkuantifikasi kemampuan model untuk membedakan setiap kemungkinan sentimen yang ada.
Optimizer dan Back Propagation
optimizer = optim.Adam(model.parameters(), lr=5e-6)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Menginisialisasi optimizer mengharuskan kita untuk mengetahui parameters model mana saja yang akan diupdate. Untuk melakukan sebuah operasi back propagation, kita perlu memanggil fungsi .backward() pada loss yang dihitung berdasarkan input dan output. Di balik fungsi tersebut, gradien yaitu hasil komputasi dari backward akan disimpan pada parameter grad jika atribut requires_grad sama dengan True. Setiap kali kita menghitung gradien, kita perlu mereset gradien dengan memanggil optimizer.zero_grad() dan fungsi optimizer.step() akan mengupdate model.
Fase Evaluasi
Di setiap pelatihan epoch, kita akan mengevaluasi performa model yang dilatih. Dalam tutorial pelatihan finetuning di atas, kita menyetel parameter set_grad_enabled sebagai True, yang memungkinkan semua gradien dihitung secara otomatis saat kita memanggil loss.backward(). Dalam fase evaluasi ini, kita tidak memerlukan parameter tersebut untuk diaktifkan, dan kita tidak ingin memperbarui parameter gradien apa pun di tensor mana pun. jadi kami menyetel parameter set_grad_enabled sebagai False.
Validasi fine tuning dilakukan dalam langkah-langkah berikut:
Aktifkan komputasi autograd dengan memanggil torch.set_grad_enabled (True).
Iterasi data loader kita valid_loader untuk mendapatkan batch_data.
Teruskan ke fungsi forward yang sama forward_sequence_classification dalam model untuk mengeluarkan prediksi model.
Evaluasi prediksi menggunakan fungsi sklearn yang disediakan dalam skrip document_sentiment_metrics_fn, untuk menghasilkan akurasi, skor F1, recall, dan precision.
Kita dapat melihat bahwa poin-poin di atas dikodekan dalam skrip evaluasi di bawah ini yang akan kita gunakan untuk mengevaluasi pelatihan fine-tuning kita.
# Evaluate on validation
model.eval()
torch.set_grad_enabled(False)
total_loss, total_correct, total_labels = 0, 0, 0
list_hyp, list_label = [], []
pbar = tqdm(valid_loader, leave=True, total=len(valid_loader))
for i, batch_data in enumerate(pbar):
batch_seq = batch_data[-1]
loss, batch_hyp, batch_label = forward_sequence_classification(model, batch_data[:-1], i2w=i2w, device='cuda')
# Calculate total loss
valid_loss = loss.item()
total_loss = total_loss + valid_loss
# Calculate evaluation metrics
list_hyp += batch_hyp
list_label += batch_label
metrics = document_sentiment_metrics_fn(list_hyp, list_label)
pbar.set_description("VALID LOSS:{:.4f} {}".format(total_loss/(i+1), metrics_to_string(metrics)))
metrics = document_sentiment_metrics_fn(list_hyp, list_label)
print("(Epoch {}) VALID LOSS:{:.4f} {}".format((epoch+1),
total_loss/(i+1), metrics_to_string(metrics)))
Skrip evaluasi di atas menggunakan fungsi document_sentiment_metrics_fn untuk melakukan penghitungan akurasi, skor F1, recall, dan metrik precision, dan berikut ini cuplikan kodenya.
def document_sentiment_metrics_fn(list_hyp, list_label):
metrics = {}
metrics["ACC"] = accuracy_score(list_label, list_hyp)
metrics["F1"] = f1_score(list_label, list_hyp, average='macro')
metrics["REC"] = recall_score(list_label, list_hyp, average='macro')
metrics["PRE"] = precision_score(list_label, list_hyp, average='macro')
return metrics
Dengan evaluasi ini, kita menyimpulkan keseluruhan proses pemodelan kita pada in IndoTutorial ini. Kami berharap Anda mendapatkan hasil yang bagus pada percobaan Anda dan kami harap Anda menikmati tutorial singkat tapi menyenangkan yang kami buat ini. Jika Anda telah menyelesaikan tutorial ini, posting pengalaman dan hasil anda di story facebook anda dan ajak dan berikan inspirasi kepada orang lain untuk melakukan hal yang sama dengan membagikan tutorial ini kepada penggemar deep learning dan NLP di seluruh Indonesia!